
Towards Rich Real-world Understanding and Controllable Navigation for Spatial Reasoning and Autonomy

Share article
Today, achieving autonomy requires custom software tailored to specific hardware platforms. This restricts the commercial value of each platform and requires significant R&D to deploy. We believe the future of autonomy revolves around software-centric solutions, that like operating systems, can be universally deployed across existing hardware platforms. This would allow a single software layer to control existing devices that can fly, walk, and roll – replacing humans with controllers today. Part of our research effort has been focused on unblocking the conditions that would allow us to arrive at this point. One of the key missing components is unified data.
We’re thrilled to unveil our first research paper, “TARDIS STRIDE: A Spatio-Temporal Road Image Dataset and World Model for Autonomy,” which breaks fresh ground in modeling dynamic real-world environments. By joining richly composable real-world imagery with early-fusion multi-modal autoregressive transformers, STRIDE and TARDIS together enable autonomous agents to see, navigate, and reason about both space and time in a unified framework.
STRIDE v1: Spatio-Temporal Road Image Dataset for Exploration
Most real-world datasets offer only static snapshots — STRIDE weaves these snapshots into a navigable, time-aware graph. Our first dataset collects and organizes 131k panoramic StreetView images, and joins them into a composable index from which we can create composable trajectories. We thus permute the dataset into 3.6 million unique observation-state-action sequences, navigating Silicon Valley — achieving a 27× boost in information without synthetic augmentation.
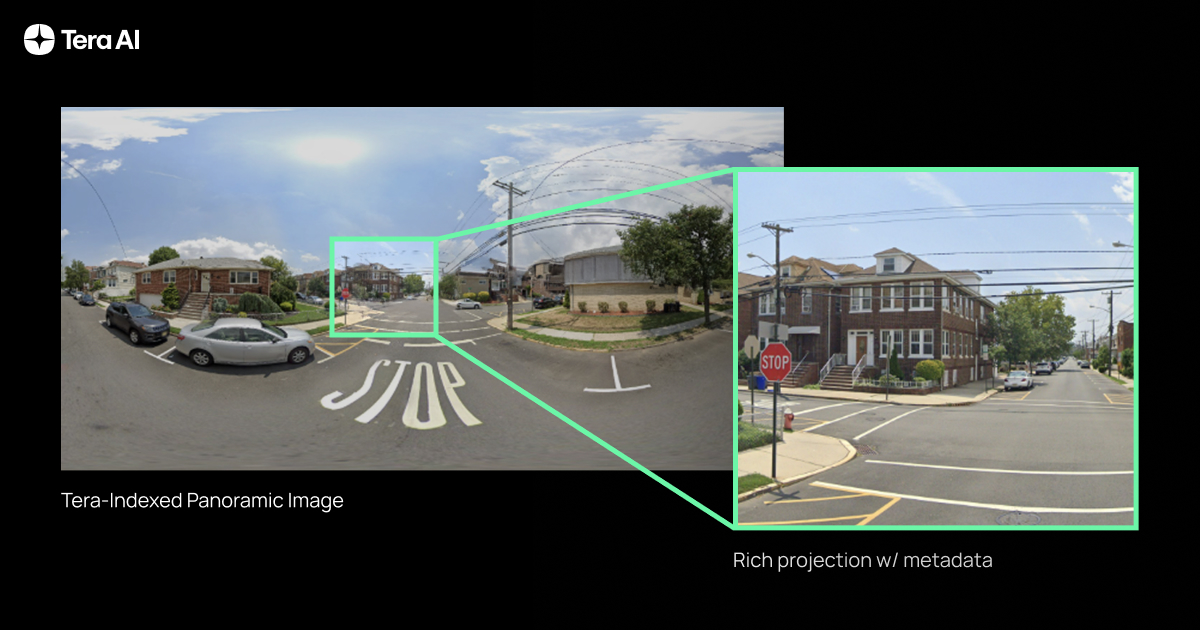
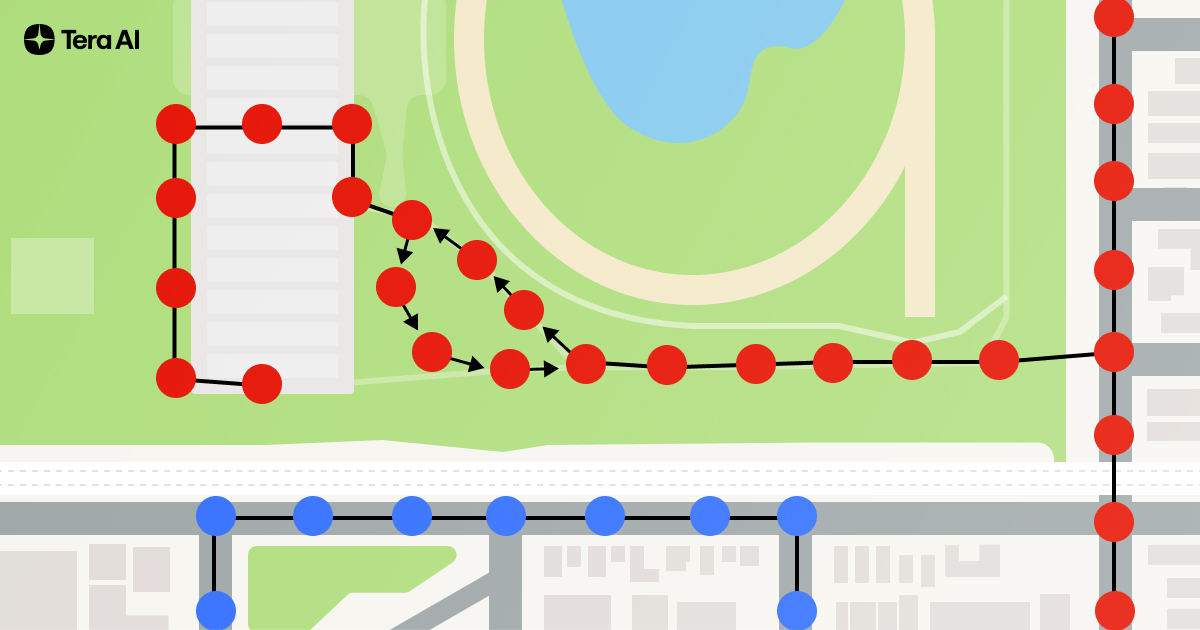

TARDIS: A World Model for Spatio-Temporal Understanding and Simulation
Built atop STRIDE, TARDIS is a 1 billion-parameter autoregressive transformer that jointly predicts where you are, how you move, and what you see next—across both space and time. Rather than separate perception, mapping, and planning modules, TARDIS weaves these tasks into a single sequential prediction loop.
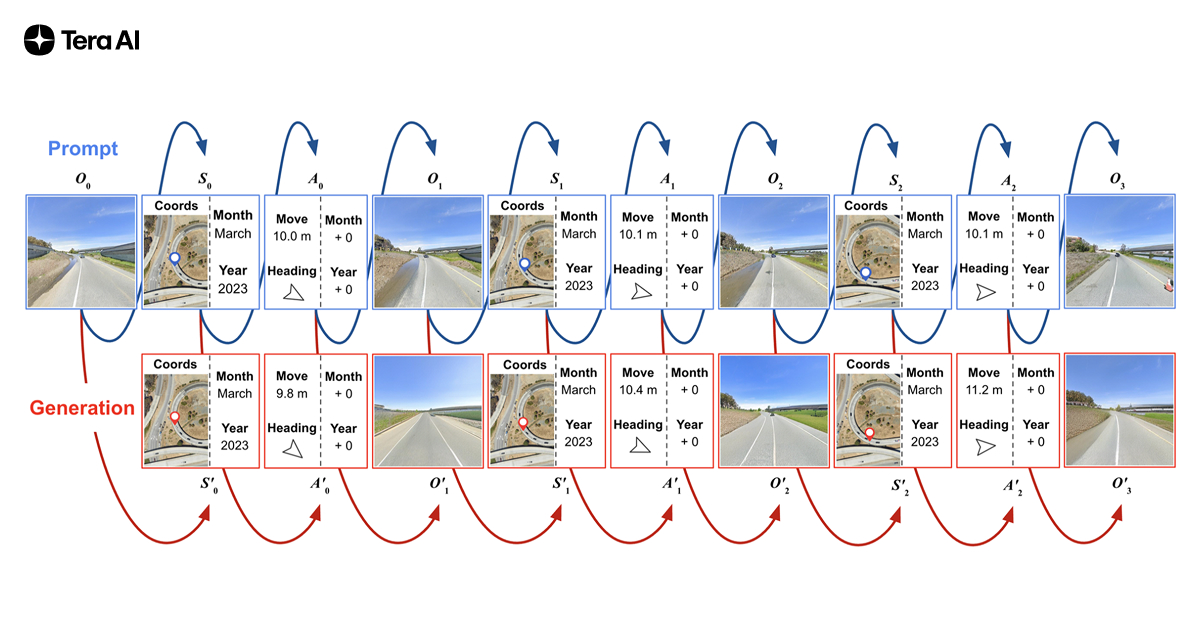

We demonstrate the following capabilities:
Controllable Photorealistic Synthesis
Prompt TARDIS with a starting view, coordinates, and movement commands—it generates realistic next frames, even across seasons. We see a 41% FID improvement over Chameleon-7B and stable SSIM across wide temporal shifts.
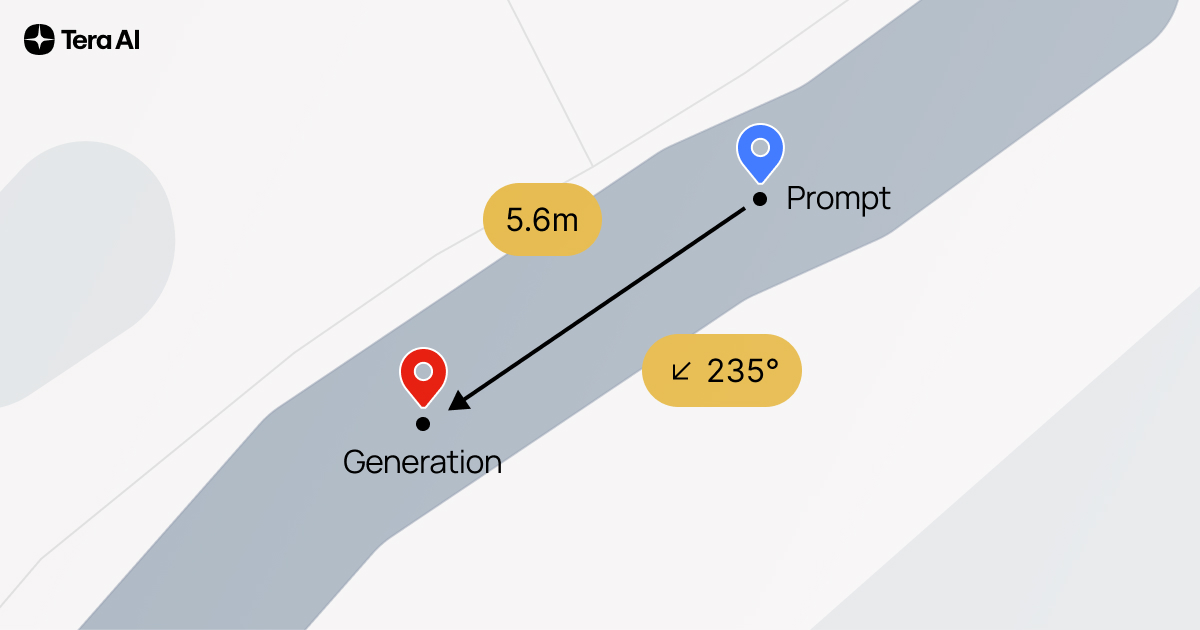
State-of-the-Art Georeferencing
Given a single street-view image, TARDIS predicts exact latitude/longitude to within 10 meters the majority of the time — over six times more accurate than leading contrastive methods within the same search radius.
Valid Autonomous “Self-Control”
When tasked to self-prompt, TARDIS generates its own move & turn actions—and 77% of those stay within road lanes, even on unseen streets and we observe emergent properties in which the model exclusively navigates onto drivable road surfaces.
Temporal Sensitivity & Adaptation
Jump forward or backward months or years: TARDIS not only shifts foliage, but also anticipates new construction or road wear, thanks to an explicit time dimension.
Why This Matters
- Robotics & Autonomous Vehicles
Empower robots and self-driving cars to navigate ever-changing streets using only cameras—no expensive lidar or high-precision GPS required. - Digital Twins & Urban Planning
Model cities over time to predict infrastructure needs, plan maintenance, or simulate emergency response. - Environmental Monitoring
Track seasonal vegetation shifts and detect anomalies like flooding or construction at scale.
What’s Next
While this work represents only an early foray of what we can share publically, we have many internal projects progressing towards exciting new directions with internal datasets and high-valued commercial use cases, including on the modeling front related to explicit map learning and navigation. Specific to this work, some immediate expansions include:
- Geographic Expansion
Scale STRIDE to new cities worldwide, capturing diverse road networks and climates. - Higher Temporal Resolution
Incorporate dashcam or drone videos for minute-level dynamics, opening doors to traffic modeling and pedestrian behavior analysis. - Multimodal Integration
Fuse lidar, radar, and map data to deepen 3D understanding and robustify predictions in adverse weather or poor lighting. - Interactive Web Experience
Launch a dynamic project page with smooth animations and user-driven playback—no slides, just immersive exploration of our data and model in action.
Additional future work will include Long-Horizon Reasoning:
Most autonomous system predictions operate on a short time horizon of just a few seconds. Our spatio-temporal world model enables reasoning about cause and effect over much longer durations, connecting events in time and space that a traditional model would miss.
Think about an experienced local driver. They don't just see the cars immediately in front of them; they have an intuitive sense of the city's rhythm. That means avoiding going by a location that their map shows as having no traffic right now because it will have traffic in 20 minutes when they get there. This is the essence of using long-horizon temporal data. Our world model learns these exact kinds of patterns. It will understand not just where the traffic is right now, but where it's going to be based on deep historical patterns.
This moves the autonomous agent from being reactive to proactive. It can make earlier route and speed adjustments, improving efficiency.
Get Started
Our full dataset, code, and pretrained TARDIS checkpoints are available now on Hugging Face
Dive in, explore the world through time, and help us push the boundaries of embodied AI!